
O livro Storytelling com Dados, da Cole Nussbaumer Knaflic, é uma das minhas maiores referências quando o assunto é visualização de dados. A autora consegue traduzir conceitos complexos de maneira prática e acessível, com exemplos reais que ajudam muito no dia a dia. Foi lendo esse livro que eu, por exemplo, abandonei (ou quase) os famosos gráficos de pizza. Não que seja proibido usar, mas ela mostra — com argumentos sólidos — por que esse tipo de visualização pode atrapalhar mais do que ajudar, principalmente quando o objetivo é comunicar de forma clara e direta.
Uma das lições mais valiosas que aprendi ao longo da minha jornada trabalhando com dados é que, se você não está sendo compreendido, o problema está em você. Ser técnico demais, usar jargões ou cálculos sem considerar o público é, muitas vezes, um sinal de falta de habilidade de comunicação. E isso, especialmente no marketing digital, pode custar caro. Não adianta apresentar um dashboard cheio de gráficos complexos se o cliente ou a equipe não entende o que aquilo significa ou como aquilo afeta a tomada de decisão.
O quarteto de Anscombe é um exemplo clássico que gosto de usar para mostrar como números iguais podem gerar interpretações completamente diferentes quando visualizados. Ele é ótimo para explicar por que a escolha do gráfico certo é tão importante — e como dois conjuntos de dados com os mesmos valores estatísticos podem ter comportamentos opostos quando colocados em um scatterplot.
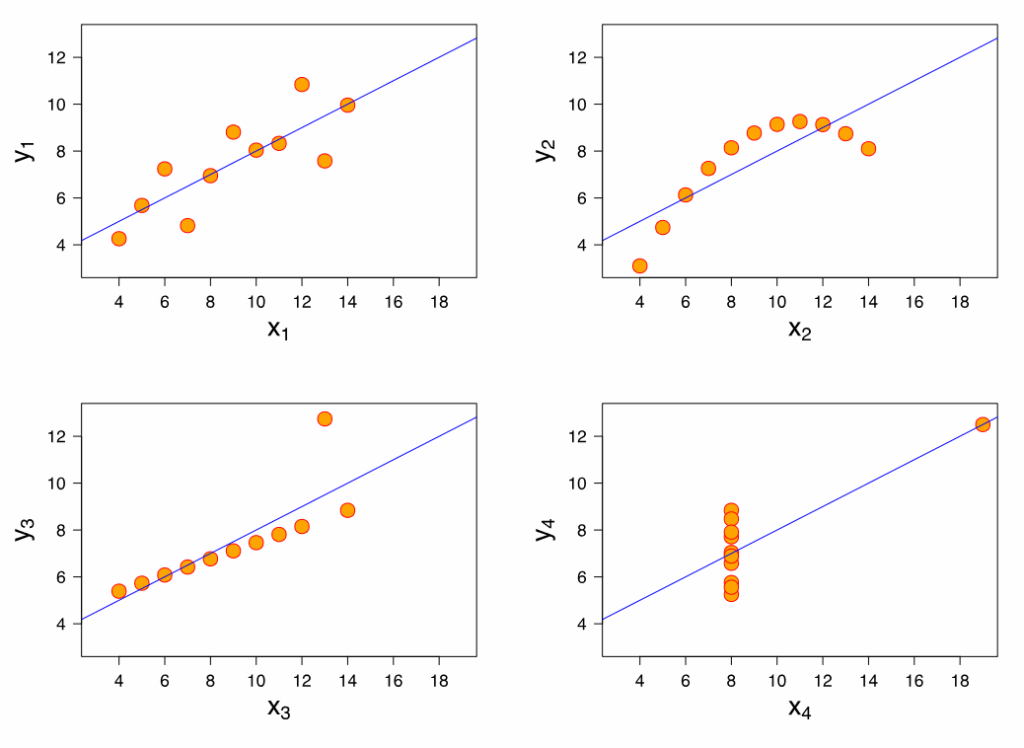
Os quatro conjuntos de dados do quarteto de Anscombe (imagem anterior) são idênticos quando analisados por estatísticas descritivas básicas, como média e variância, mas apresentam diferenças visuais significativas quando representados graficamente.
Eu digo sempre que no campo da visualização de dados, há vários desafios, mas os maiores deles estão relacionados a mostrar a correlação nos dados.
Relação entre variáveis com Scatterplot
O scatterplot (ou gráfico de dispersão) é muito útil, especialmente quando queremos cruzar duas variáveis e entender sua relação. Por exemplo, dá pra usar esse tipo de gráfico para combinar o investimento em mídia com retorno (ROAS), ou tempo de permanência no site com taxa de conversão. Dá até pra inserir uma terceira variável com cores ou tamanhos dos pontos, mas isso deve ser feito com cuidado, senão a leitura pode ficar poluída.
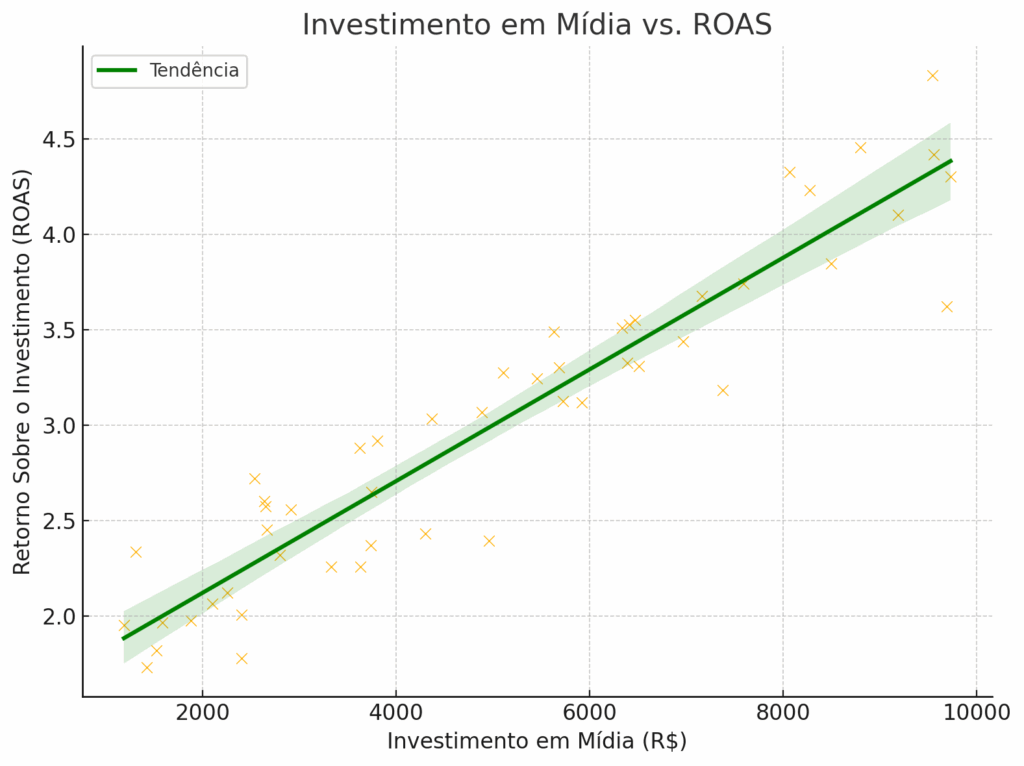
Costumo utilizar esse tipo de gráfico para ilustrar aos meus clientes as relações entre variáveis. Note que nesse gráfico coloquei até uma faixa de tendência, demonstrando a relação entre as variáveis.
Matrizes de correlação
As matrizes de correlação também são ferramentas poderosas. Elas mostram o grau de correlação entre variáveis numéricas — quanto mais escura a célula, mais forte a correlação (positiva ou negativa). No marketing digital, você pode usar uma matriz de correlação para identificar quais métricas estão mais relacionadas com a conversão, por exemplo: será que a taxa de rejeição está negativamente correlacionada com o tempo de permanência? Será que a quantidade de sessões impacta diretamente o número de leads gerados? Esse tipo de análise ajuda a direcionar estratégias com base em dados e não em achismos.
Aqui está um exemplo de matriz de correlação com métricas típicas do marketing digital: sessões, taxa de rejeição, tempo médio na página, páginas por sessão, conversões e leads gerados.
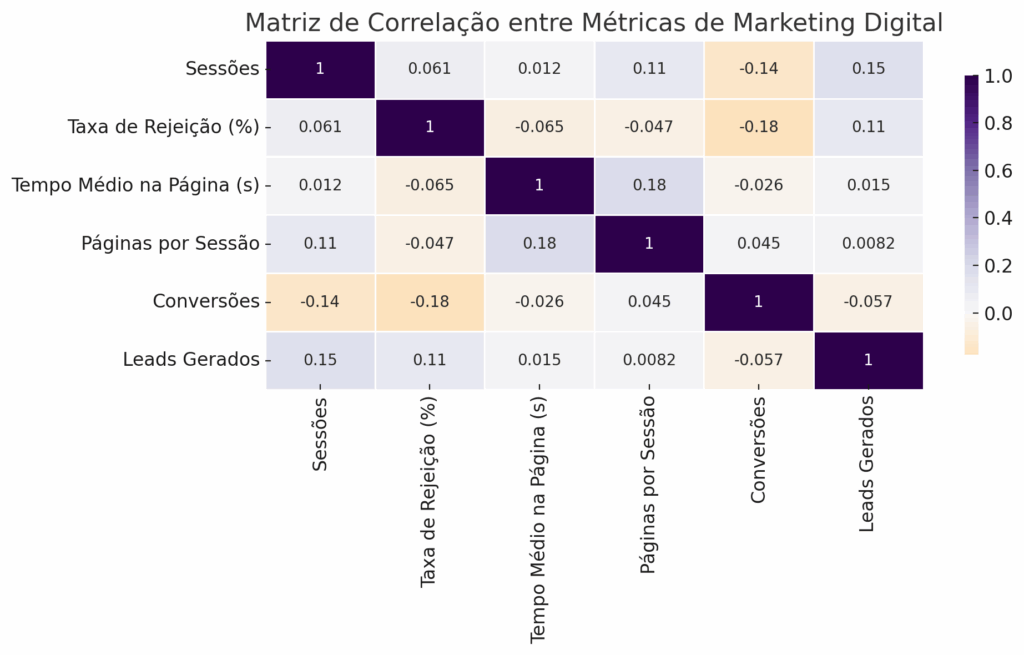
Neste gráfico, as células mais escuras indicam correlações mais fortes (positivas ou negativas). Por exemplo:
- Se a célula entre tempo na página e páginas por sessão estiver bem clara ou escura com valor alto, isso indica que quando uma aumenta, a outra tende a aumentar também (correlação positiva).
- Já uma correlação negativa, como entre taxa de rejeição e conversões, sugere que quando uma sobe, a outra tende a cair — o que é esperado no comportamento de um site bem otimizado.
Esse tipo de análise permite identificar relações relevantes para orientar decisões de otimização.
No fim das contas, visualização de dados não é só escolher um gráfico bonito. É sobre pensar no público, no objetivo da análise e na mensagem que você quer comunicar. E isso, no marketing digital, faz toda a diferença, principalmente se o qua você está procurando demonstrar é o esforço e resultados das suas ações.
Como usar a correlação de Pearson para construir essa visualização?
A Correlação de Pearson, também chamada de coeficiente de correlação de Pearson ou Pearson’s r, é uma medida que avalia a relação linear entre duas variáveis quantitativas.
Ela foi proposta por Karl Pearson e é amplamente utilizada em:
- Análise exploratória de dados
- Modelagem estatística
- Estudos científicos
- Machine Learning
- Business Intelligence
O resultado da Correlação de Pearson é um número que varia entre -1 e +1.
A fórmula matemática do coeficiente de correlação é:
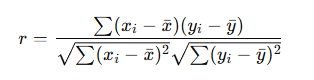
Onde:
- e são os valores observados
- e são as médias das variáveis
- é o coeficiente de correlação
Intuitivamente, essa fórmula mede quanto as variáveis variam juntas em relação à sua variabilidade individual.
Como interpretar o coeficiente de correlação?
A interpretação da correlação depende do valor do coeficiente .
Valores possíveis do coeficiente de correlação
| Valor de r | Interpretação |
|---|---|
| r = +1 | Correlação positiva perfeita |
| r próximo de +1 | Forte correlação positiva |
| r próximo de 0 | Ausência de correlação linear |
| r próximo de -1 | Forte correlação negativa |
| r = -1 | Correlação negativa perfeita |
Usando R para fazer a correlação de Pearson
Você pode utilizar a linguagem R para fazer a correlação de Pearson. A seguir desenvolvi um exemplo prático para calcular a Correlação de Pearson entre:
- Investimento em mídia (R$)
- ROAS (Return on Ad Spend)
O objetivo é entender: quando o investimento aumenta, o retorno proporcional também aumenta?
| Mês | Investimento (R$ mil) | ROAS |
|---|---|---|
| Jan | 10 | 2.1 |
| Fev | 15 | 2.4 |
| Mar | 20 | 2.8 |
| Abr | 25 | 3.0 |
| Mai | 30 | 3.4 |
Olhando a tabela, é possível notar que sim! Mas eu posso provar isso com Pearson!
investimento <- c(10, 15, 20, 25, 30)
roas <- c(2.1, 2.4, 2.8, 3.0, 3.4)
cor(investimento, roas, method = "pearson")O resultado é 0.9961165. Esse número é muito próximo de zero, sendo assim, olhando para a tabela “Valores possíveis do coeficiente de correlação” temos uma “Forte correlação positiva”.
Correlação de Pearson no Python
Eu prefiro fazer esse tipo de coisa no R, pois é bem mais fácil, mas também pode ser feito com a linguagem Python:
import numpy as np
investimento = np.array([10, 15, 20, 25, 30])
roas = np.array([2.1, 2.4, 2.8, 3.0, 3.4])
np.corrcoef(investimento, roas)[0,1]FAQ
O que significa relação entre variáveis?
Uma relação entre variáveis ocorre quando mudanças em uma variável estão associadas a mudanças em outra.
Essa relação pode ser:
– Linear
– Não linear
– Positiva
– Negativa
– Forte ou fraca
– Estatisticamente significativa ou não
Nem toda relação é causal — muitas são apenas associativas.
Qual a diferença entre correlação e associação?
Correlação é uma medida estatística numérica (como o coeficiente de Pearson).
Associação é um conceito mais amplo, que indica que duas variáveis apresentam algum tipo de dependência, mesmo que não linear.
Toda correlação é uma associação.
Nem toda associação pode ser medida por correlação linear.
O que é covariância e qual a diferença para correlação?
A covariância mede a variação conjunta entre duas variáveis.
A diferença é que:
– A covariância depende da escala das variáveis.
– A correlação padroniza essa medida, sempre variando entre -1 e +1.
A correlação é, na prática, uma versão normalizada da covariância.
O que são outliers e como afetam a correlação?
Outliers são valores extremos que destoam do padrão dos dados.
Eles podem:
– Inflar artificialmente o coeficiente
– Reduzir a correlação
– Criar uma falsa impressão de relação
Sempre visualize os dados antes de interpretar o coeficiente de correlação.