
A sigla ETL vem do inglês “Extract, Transform and Load”. Traduzindo para o português, significa a extração, transformação e o carregamento de dados. Trata-se de uma etapa importante nos processos de ciência de dados, cujo objetivo é atingir uma melhor qualidade dos dados, para serem confiáveis e possam fornecer informações importantes para a tomada de decisão. A seguir abordo como funciona esse processo e algumas das suas principais características.
O que é o ETL?
ETL é quando os dados são extraídos de uma fonte, transformados no sentido de padronização, correção, entre outros métodos de limpeza de dados, e carregados em um local para que possam ser manipulados e analisados. De uma forma simples é isso!
📋 Organize Seu Processo de ETL
Baixe grátis o checklist completo com 20 etapas essenciais para implementar ETL com sucesso!
✨ Acessar Checklist InterativoComo acontece o processo de ETL?
Boa parte do trabalho dos estudos de dados, são os processos de ETL, afinal, os dados são oriundos de sistemas transacionais, que permitem a operação de uma empresa. Eles precisam ser extraídos e depois tratados, antes de serem carregados em um sistema que possibilitará a realização de análises e cruzamentos de informações.
Se imaginarmos uma empresa e suas diversas áreas, em cada uma delas encontraremos sistemas transacionais, especialistas em funções diferentes, definidos para resolver algum tipo de processamento de dados em seus respectivos departamentos.
Em uma arquitetura para a utilização de um data warehouse, por exemplo, algumas fases são consideradas para o tratamento de dados oriundos dos sistemas transacionais.
Primeiro os dados são extraídos de sistemas, podem ser armazenados em um staging area, antes de serem transformados. Pode ser um banco de dados que servirá de ambiente pré-transformação e carga.
A fase de transformação, é necessária, uma vez que os dados podem vir em diversos formatos, padrões, estruturados ou não. Por exemplo, cada sistema pode ter um formato de data diferente, o que pode causar problemas na hora de realizar as análises. Sendo assim, os dados são higienizados (campos vazios, registros duplicados), padronizados (unidades numéricas, datas, etc) e contextualizados.
E por último os dados são carregados, disponibilizados em um banco de dados, para que possam ser estudados por um analista, que usará ferramentas de visualização de dados como o Looker Studio, Power BI, Tableau, entre outras, para montar seus dashboards. Em alguns casos poderá realizar análises mais profundas com programas desenvolvidos em R ou Python.
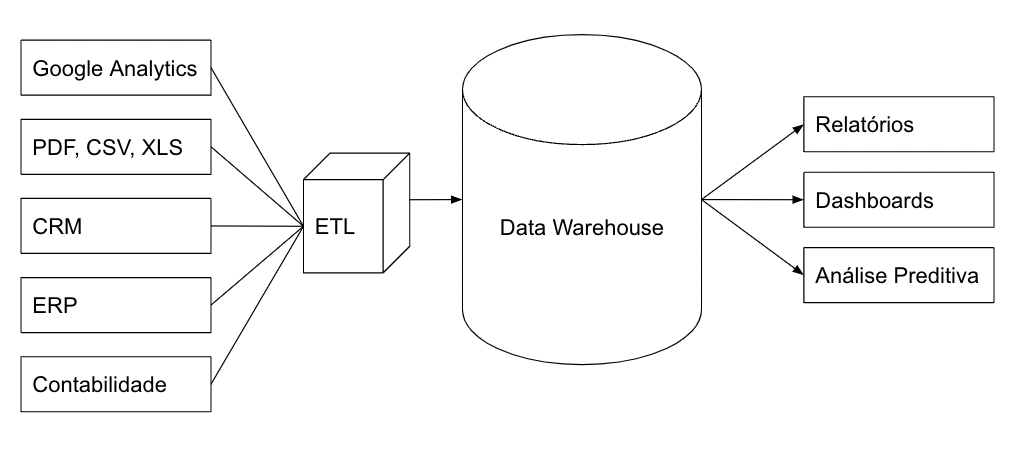
Depois dessas etapas, os dados ficam prontos e disponíveis para estudos e combinações que possibilitarão a transformação deles em informações úteis para a tomada de decisões.
Ferramentas Comuns de ETL
Quando falamos em ETL na prática, é importante conhecer as ferramentas mais usadas no mercado, porque são elas que permitem transformar a teoria em operação real dentro das empresas. Hoje, existem soluções robustas que atendem desde projetos menores, como o de uma equipe que precisa consolidar dados de CRM e Analytics, até arquiteturas complexas que envolvem ambientes multinuvem, centenas de fontes e pipelines altamente orquestrados.
Entre as ferramentas mais tradicionais, o Pentaho Data Integration se destaca pela facilidade de modelar fluxos com componentes visuais e ampla capacidade de integração. Já o Talend é muito usado por equipes de engenharia de dados que precisam de pipelines mais escaláveis e flexíveis, além de oferecer recursos avançados para manipulação de dados em larga escala.
No ecossistema de nuvem, o AWS Glue se tornou comum em projetos modernos por eliminar boa parte do trabalho manual, automatizar Catálogos de Dados e permitir pipelines serverless, sem a necessidade de administrar servidores.
Outras ferramentas populares incluem o Apache Nifi, utilizado para fluxos contínuos e streaming; o Informatica PowerCenter, muito presente em grandes corporações por sua robustez; e o Azure Data Factory, preferido por empresas que utilizam o ecossistema Microsoft e precisam orquestrar cargas em ambientes híbridos. Em cenários mais recentes, plataformas como Fivetran e Stitch têm crescido por simplificar a etapa de extração com conectores prontos, acelerando o tempo de implementação e reduzindo custos operacionais.
Cada uma dessas ferramentas atende necessidades diferentes, mas todas cumprem o mesmo propósito: facilitar a extração, a transformação e o carregamento dos dados, permitindo que analistas, engenheiros e equipes de BI foquem na parte estratégica da análise, e não na manutenção manual de processos.
Como agilizar o ETL.
Existem algumas boas práticas que podem facilitar e dar alguma celeridade para o processo de ETL.
Verifique quais são os horários mais adequados para obter uma maior disponibilidade dos dados na hora da extração. Isso é fundamental. Um vez tentei realizar a extração em um momento de operação plena de um sistema. Isso congestionou o fluxo dos dados, estressou o processamento de dados ativo, o que deixou tudo mais lento. Um caos!
Geralmente, para alguns sistemas, o processo de extração pode não causar nenhum problema de performance. Outros, talvez pela forma que foram desenvolvidos, podem ter esse problema. Sendo assim, procure realizar esse processo em horários de menor movimento. Algumas organizações fazem a extração e transformação de grande quantidade de dados, no período da noite, em horários de baixo fluxo de processamento de dados.
Projeto da padronização dos dados.
Pense seriamente em ajudar a projetar a coleta de dados para melhorar a qualidade deles, diminuindo o tempo de tratamento. Considere já padronizar o formatos dos dados imputados em um sistema, pelo usuário ou um sensor, logo no momento da coleta. Se o sistema que faz a captação, produz um dado com algum tipo de erro, ele precisará ser tratado, o que atrasará o processo. O fato é que esse trabalho pode muito bem ser mais veloz, quando os dados já vem com alguma padronização.
Eu já tive situações, em trabalhos com tabelas sem uma quantidade tão significativa de registros, onde fiquei um tempo considerável encontrando problemas e fazendo uma transformação para fazer a padronização de unidades, corrigir a grafia correta de dados, verificar padrões numéricos, de datas, entre outros. Agora, imagine isso em uma quantidade massiva de dados.
Em um trabalho frequente que eu tinha de ETL, para um sistema que enviava dados de eventos, para que eu fizesse relatórios, perdia muito tempo na fase de transformação dos dados. Em uma reunião com os envolvidos na coleta de dados, projetamos soluções que padronizaram a alimentação de dados no sistema, e assim, conseguimos agilizar todo o processo onde a fase de transformação, quase não era necessária.
Automatizando o processo.
Automatizar o processo de transformação também é uma solução muito inteligente. Vamos supor que sua origem de dados é uma planilha e eles precisam ser importados para um banco de dados que está recebendo informações de outras fontes também. Você pode criar um programa em Python ou em R que irá automatizar a coleta desses dados, a transformação deles e o carregamento no banco de dados.
No trecho de código a seguir, mostro um exemplo de transformação usando Python. Nele, é feito o tratamento de correção para o nome de estado, de modo que, o padrão seja sempre “São Paulo”. Dessa forma, não haverá uma tabela estado com registros considerando “SP”, “Sao Paulo” e “São Paulo”, como estados diferentes.
dados.loc[dados['Estado'].isin(['Sao Paulo','SP']), 'Estado'] = "São Paulo"
dados.groupby(['Estado']).size()Eu consigo imaginar várias medidas para evitar esse tipo de erro na hora da inserção de dados pelo usuário, por isso, como mencionei anteriormente, é tão importante a participação do analista de BI no projeto do sistema.
É necessário usar todos os dados?
Pense que quanto maior o número de dados, maior o tempo de tratamento, possíveis problemas de compliance, performance do banco de dados, entre outros.
O que é realmente necessário tratar, a diferença que um dado fará em seu banco, são perguntas pertinentes.
Antes de extrair os dados, faça os questionamentos necessários, pois podem evitar que você tenha problemas no futuro, principalmente se você está usando um banco de dados na nuvem. Além de performance e espaço, dados desnecessários armazenados, podem aumentar o custo da ferramenta.
Por exemplo: para um projeto onde você fará análises preditivas de séries temporais, faz diferença dados como endereço, local de nascimento, CPF ou RG? Certamente que não.
Como posso planejar meu processo de ETL?
- Faça um planejamento do processo. Quem estará envolvido, tempo decorrido, periodicidade, etc;
- Considere os sistemas que serão as origens de dados, os formatos que os dados são extraídos e as limitações;
- Quais os dados são necessários na extração e as regras de governança de dados;
- Onde será o staging area dos dados extraídos;
- Como será o sistema de transformação, manual ou automatizado?
- Elabore um processo de controle de qualidade, um esquema de teste para validar o sucesso da transformação. Nomeie um responsável, ou um comitê (dependendo do tramanho do trabalho), quem será o responsável por fazer essa validação, com base em uma taxa amostral.
Perguntas Frequentes sobre ETL
Qual a diferença entre ETL e ELT?
A principal diferença está na ordem das operações. No ETL tradicional, os dados são transformados antes de serem carregados no destino. Já no ELT, os dados são carregados primeiro em seu formato bruto e depois transformados no próprio sistema de destino. O ELT é mais comum em ambientes de cloud computing com grande capacidade de processamento.
Quanto tempo leva para implementar um processo de ETL?
O tempo varia significativamente dependendo da complexidade do projeto e dos dados disponíveis. Processos simples podem levar dias ou semanas, enquanto implementações complexas podem levar meses. Fatores que influenciam incluem: número de fontes de dados, volume de dados, complexidade das transformações e qualidade dos dados originais. Extrações como de ferramentas de Web Analytics, de períodos curtos, você pode fazer todo o processo em menos de uma hora, se já tem alguma experiência e bons processos.
Preciso saber programação para trabalhar com ETL?
Depende da ferramenta e da complexidade. Existem ferramentas visuais de ETL que permitem criar pipelines através de interfaces gráficas. No entanto, conhecimento em programação (especialmente Python, SQL ou linguagens similares) é muito valioso para criar transformações mais complexas, automatizar processos e resolver problemas específicos. Posso dizer por experiência própria que saber programar em Python, me ajudou muito em processos, principlamente, de transformação de dados.
Quais são os principais desafios em processos de ETL?
Os desafios mais comuns incluem:
Qualidade dos dados: dados inconsistentes, duplicados ou incompletos – na minha visão um dos principais desafios, pois os dados nunca estão todos “certinhos”, “bonitinhos”, esperando você! Na verdade gosto de entender sempre qual o nível de mínimo de qualidade aceitável. Dados oriundos de sistemas Web Analytics, principalmente, certamente vão ter uma margem de erro que precisa ser considerada.
Performance: processar grandes volumes de dados dentro de janelas de tempo aceitáveis – principalmente com pressão de prazos visto a competição e o timing de campanhas e projetos.
Manutenção: mudanças nas fontes de dados que quebram os pipelines existentes.
Monitoramento: detectar e corrigir falhas rapidamente.
Governança: garantir conformidade com regulações de privacidade e segurança. Esse é outro grande ponto de atenção, visto que embora os princípios sejam o mesmo, dependendo do país, algumas coisas mudam.
Posso fazer ETL com dados não estruturados?
Sim, é possível trabalhar com dados não estruturados (como textos, imagens, áudios, vídeos) em processos de ETL, mas requer técnicas especializadas. Geralmente envolve extrair metadados, aplicar técnicas de processamento de linguagem natural, análise de imagens ou outras formas de estruturação antes de carregar os dados para análise. É bem mais complicado, na minha opinião, do que o trabalho com dados estruturados.
ETL consome muitos recursos computacionais?
Pode consumir, especialmente quando se trabalha com grandes volumes de dados. Por isso é importante: executar processos em horários de baixo uso dos sistemas de origem; otimizar queries e transformações (alguns bancos de dados cobram por consultas, fique atento!); considerar processamento paralelo quando possível; dimensionar adequadamente a infraestrutura (eu quase parei uma empresa, por não me atentar para isso!); extrair apenas os dados necessários.
Preciso de ferramentas especializadas para fazer ETL?
Não necessariamente. Você pode criar processos de ETL usando linguagens de programação como Python ou SQL. No entanto, ferramentas especializadas podem oferecer vantagens como interfaces visuais, monitoramento integrado, conectores pré-construídos para diversas fontes de dados e recursos de orquestração. A escolha depende da complexidade do projeto e dos recursos disponíveis.