
Ao iniciar a análise de um conjunto de dados é necessário entender suas características, possíveis problemas, entre outras particularidades que podem ajudar o cientista de dados no decorrer do estudo. A seguir explico o que é a análise exploratória de dados e como pode ser feita com a ajuda do R.

O que é uma análise exploratória de dados?
Também conhecida pela sigla AED, a análise exploratória de dados é usada para investigar conjuntos de dados, entender e resumir suas características, como estão distribuídos, calcular médias, mediana, verificar a existência de registros não preenchidos, entre outras ações oriundas dessa observação. Ela emprega técnicas quantitativas e gráficas.
Foi muito difundida pelo estatístico norte-americano John Turkey, que defendia a exploração de dados para formulação de hipóteses, experimentos e planejamento.
Por que a análise exploratória é importante?
Ter esse primeiro contato é importante, para que você possa entender o que está acontecendo no conjunto. Analistas de dados, precisam ser curiosos como investigadores. Começar uma série de cálculos ou mesmo um estudo sem um olhar inicial, pode prejudicar interpretações futuras.
Nas primeiras investigações é possível perceber:
- inconsistências nos nomes, como diversas abreviações para o mesmo significado (masc, masculino, homem, para nomear o gênero masculino, por exemplo);
- colunas mal tituladas com palavras em língua estrangeira ou que possam causar qualquer tipo de confusão;
- outliers, dados fora da tendência padrão;
- dados numéricos e categóricos; e
- outras percepções importantes, para que você já tenha uma ideia do trabalho que vai ter pela frente.
Compreensão dos dados no R.
Há várias metodologias, técnicas e opiniões sobre como fazer uma análise exploratória de dados. Ela precisa, no mínimo, considerar: o carregamento dos dados; a visualização inicial; ajustes mínimos; e a apresentações via gráficos. Certamente o R pode facilitar, muito, a sua vida.
Importação dos dados.
Primeiramente é necessário importar os dados necessários para fazer a análise exploratória. Eles podem vir de várias formas, mas, em boa parte dos casos é possível fazer o download de arquivos com extensões .csv. Normalmente eles já são oferecidos nesse formato pela maioria dos softwares.
A seguir, será usada a função read.csv para importar os dados para o programa. O argumento sep serve para mostrar ao R qual o separador que está sendo usando. Perceba que importo o conjunto de dados e depois guardo ele dentro de um vetor, chamado visitas.
visitas = read.csv("visitas-site.csv", sep = ",")
visitas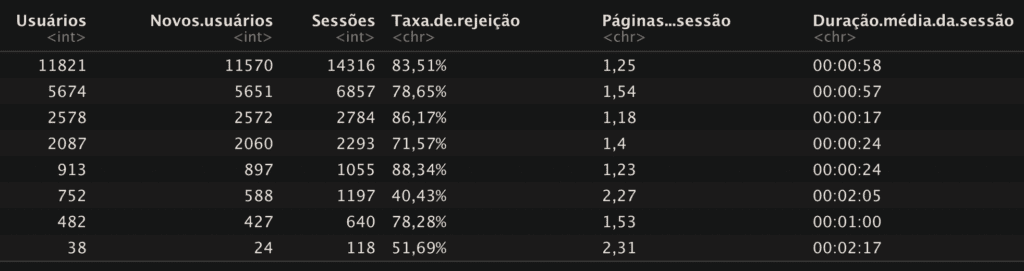
Visualizando os dados pela primeira vez.
Você pode olhar o conjunto inteiro, chamando o vetor onde guardou os dados, contudo algumas tabelas podem ter centenas de registros, nesse caso, recomendo olhar o início dos dados, com seus respectivos cabeçalhos, para ser possível observar as colunas, tipos, etc. Basta usar o head:
head(visitas)Verifique também o final do conjunto através do tail:
tail(visitas)Tente fazer um comparativo rápido, do começo e fim do conjunto, observando mudanças e outras características.
Arrumando o nome das colunas e linhas.
Em alguns casos pode ser necessário mudar os nomes das colunas, afinal, podem conter siglas, termos em outro idioma, nomes complicados, que dificultam o entendimento do analista e até causar confusões. É possível renomear, usando a função colnames().
As colunas precisam ser renomeadas na sequência que estão no conjunto (observe na imagem 01 a sequência original). Caso queira manter algum nome, basta repeti-lo. Para o caso de conjuntos que venham sem nome nas colunas, adote o mesmo procedimento.
colnames(visitas) = c("usuários","novos", "sessões", "rejeição", "página/sessão", "duração média")Também é possível inserir (ou mudar) os nomes das linhas, basta usar a função row.names(). A seguir, são nomeadas as linhas, sendo oito períodos no conjunto, como meses do ano.
row.names(visitas) = c("jan", "fev", "mar", "abr", "mai", "jun", "jul", "ago")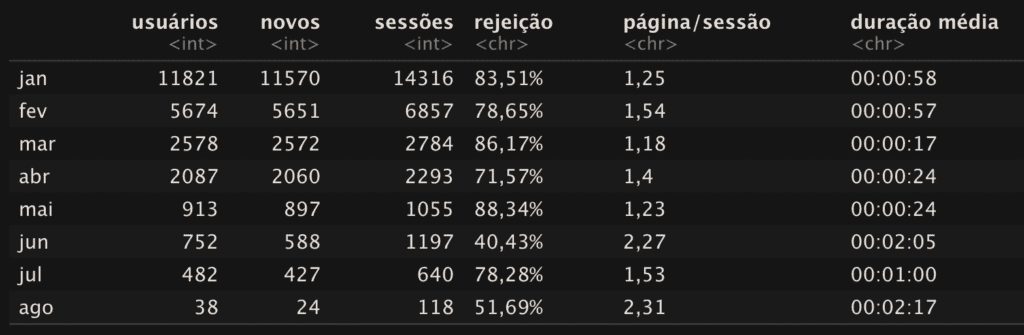
Analisando o resumo dos dados.
Para ter uma rápida visão, um resumo do conjunto de dados, use o summary(). Você também pode usar o describe().
summary(visitas)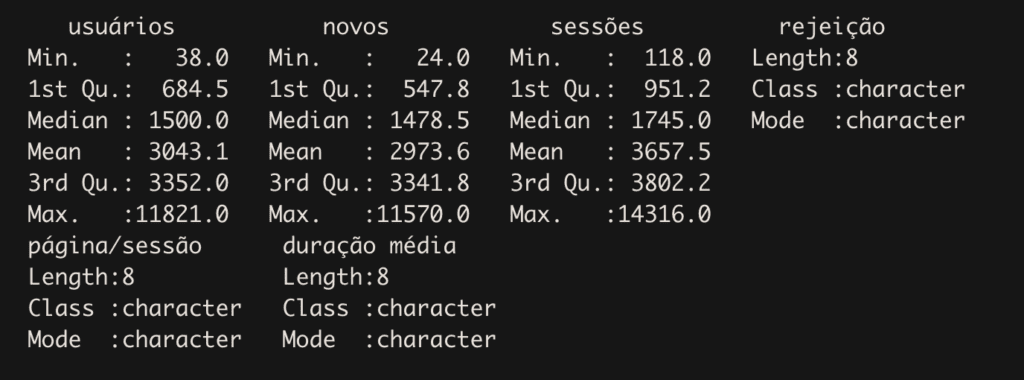
describe(visitas)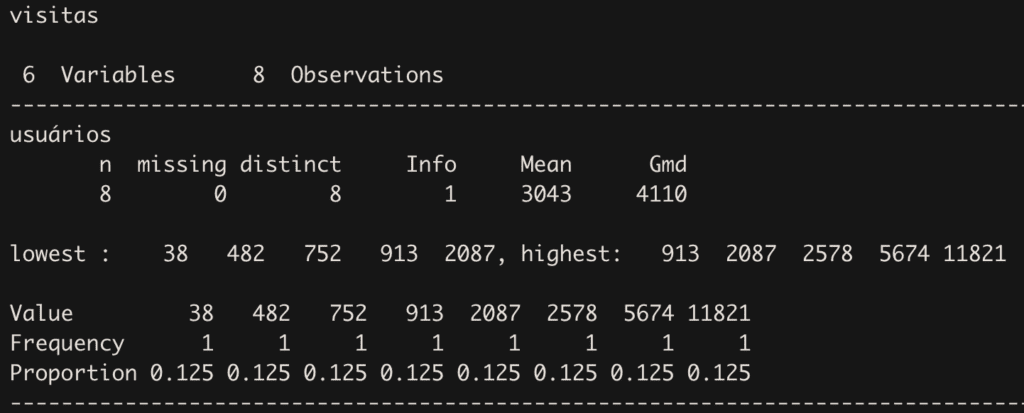
É possível usar essas funções para avaliar somente uma coluna, para isso basta usar o describe(seuconjuntodedados$coluna) ou summary(seuconjuntodedados$coluna).
Caso você tenha uma série temporal com mais de dois períodos, pode usar a função decompose(seuconjuntodedados), pois ela mostra dados de sazonalidade, tendências, ruídos, entre outros dados estatísticos importantes.
Fazendo gráficos para realização de primeiras análises.
A observação de dados através de gráficos torna mais simples a análise. Sendo assim, você pode “plotar” alguns deles, para entender melhor o que está acontecendo, padrões, outliers e tendências. A seguir, eu faço isso com a coluna usuários, do conjunto visitas.
plot(visitas$usuários, type = "l", xlab = "Período", ylab = "Frequência")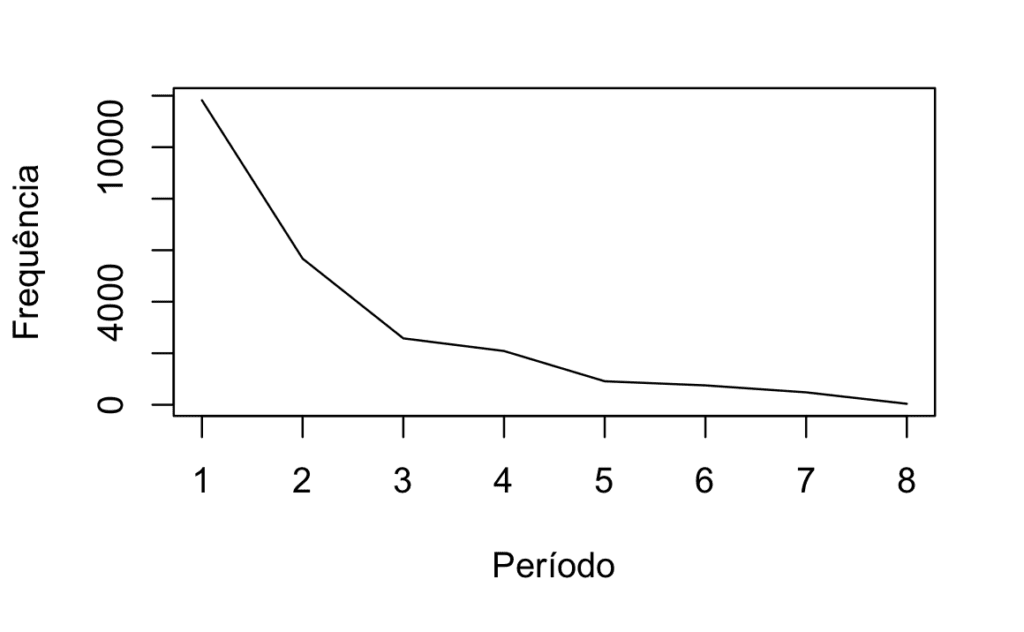
Se eu quero fazer, por exemplo, um gráfico da decomposição de uma série, para observar tendências, ruídos, etc, posso usar o plot também. Como exemplo, uso o dataset AirPassangers, abaixo.
plot(decompose(AirPassengers))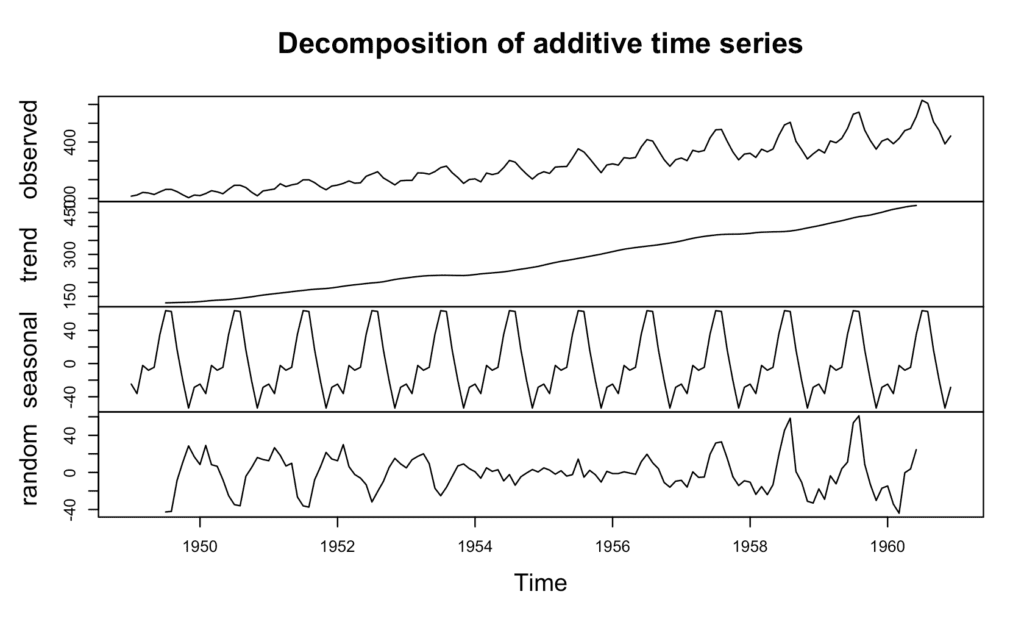
Qual o objetivo aqui? É, através de gráficos, observar o comportamento dos números e suas distribuições, visualmente. Posso notar tendências sazonais, que podem colaborar para a tomada de decisões.
O importante é entender que aqui não há uma receita pronta. Você pode usar os gráficos que quiser (boxplot, pie, barplot, etc). Escolha suas ferramentas e depois vá lapidando suas conclusões.
Conclusões
A análise exploratória de dados vai permitir que o cientista de dados observe as principais características do conjunto de dados.
A partir desse ponto, você está pronto para limpar e tratar os dados, fazer outras análises e enriquecer as informações que irá apresentar nos seus relatórios.
Olá!
Onde posso baixar o arquivo “visitas-site.csv” ?